
Training Generative Adversarial Networks (GANs)
Published:
What is a GAN?
Generative Adversarial Networks (GANs) were introduced in this paper by Ian Goodfellow and other researchers located at the Universite de Montreal. A Generative Adversarial Network falls into the cateogry of generative models, that have the ability to produce new content. A particular GAN, utilizes both generative and discriminative models, the two distinguished classes defined in statistical classification. A clear discriminating definition between the two is that discriminative models learn boundaries between classes while generative models models the distrirbution of individual classes.
MLEngineer has also written a quick analogy to illustrate generative v discriminative models. Some standard examples of the two could include as generative classifiers: naive bayes classifier and linear discriminant analysis; discriminative models: logistic regression.
TL;DR The generator produces new images and passes it to the discriminator model that decides if image it receives is a fake.
How do GANs actually work?
A classic analogy for a GAN takes the case of the police (discriminator) and the counterfeiter (generator). The counterfeiter (generator) creates new images and passes it to the police (discriminator), where the generated images gets evaluated for its authenticity. The police (discriminator) then provides feedback by comparing generated images with real images. The police (discriminator) strives to identify the images coming from the counterfeiter (generator) as fake whilst the counterfeiter (generator) seeks to generate images authentic enough to pass as real.
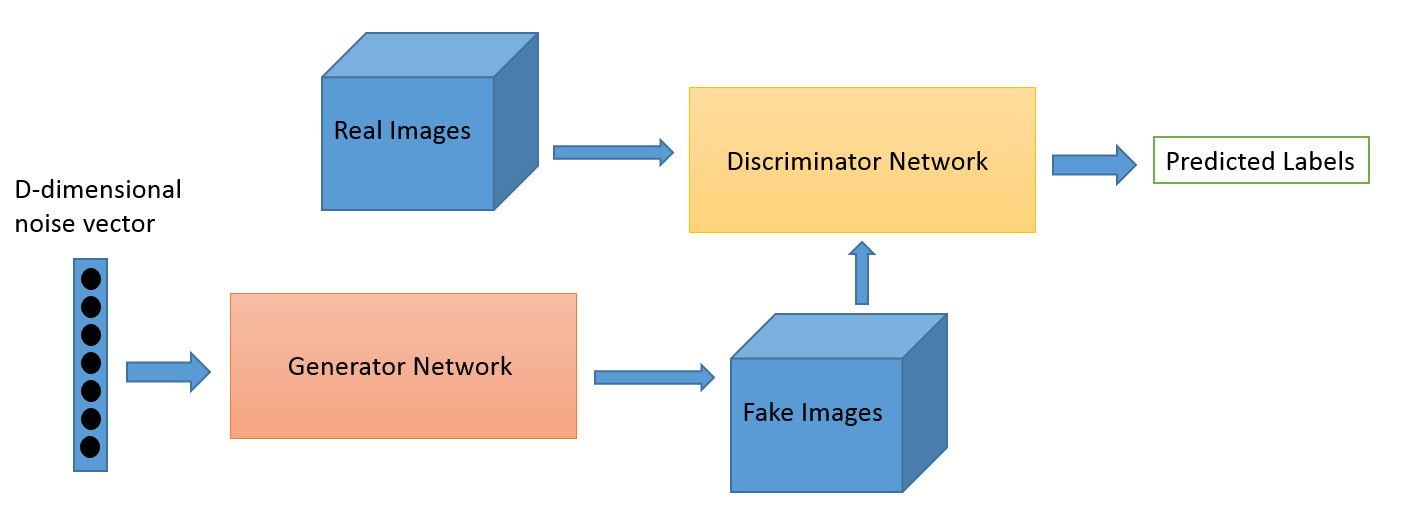
Credit: O’Reilly
- The generator initially takes in random noise and returns an image/text
- This generated image is passed to the discriminator with a collection of real images from the dataset
- The discriminator then takes in the images and generates a probability to determine if the generated image is real (1) or fake (0) , generating a feedback loop.
The generator in turn learns to create more believable data to fool the discriminator while the discriminator learns to better discriminate between the fake and real samples. The optimal generator would be fed a z-dimensional vector (as seen in code), where there may be dimensions that represent specific features that offer a useful representation automatically. The generator seeks to find the optimal true probability distribution that best represents the object (in the case of MNIST, the numbers), at each iteration minimizing the error distance between the generated and the true probability distribution as illustrated below. 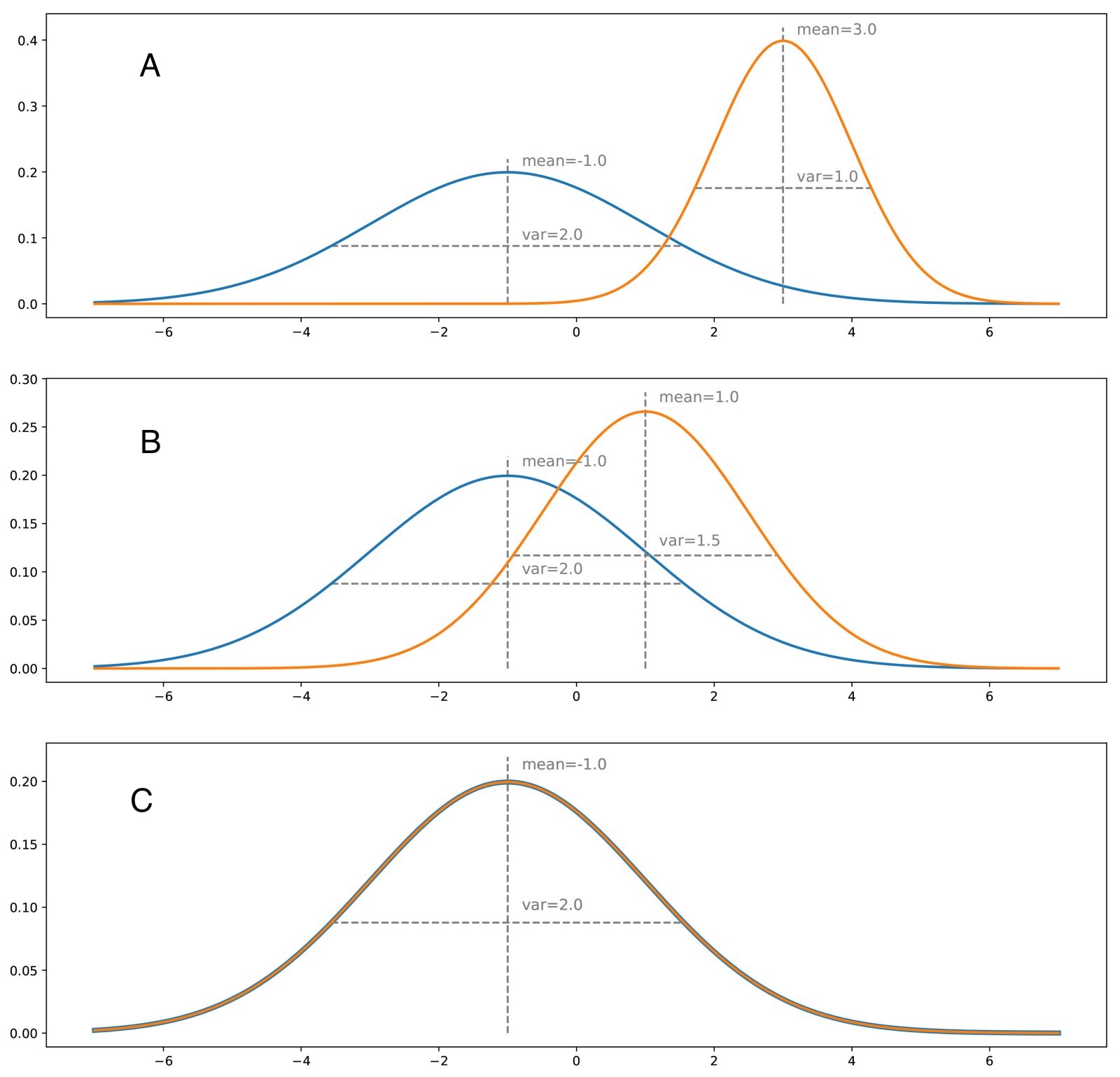 Credits: Rocca.
Credits: Rocca.
For distribution A illustrated in the above figure, given the distance between the two distributions, the discriminator would easily tell apart/classify most of the points presented to it. However, the same cannot be said for C, where the distributions are relatively close in all the points.
Joseph Rocca wrote an incredible blog post into understanding the step-by-step mechanics of GANs where he illustrates:
- how the generator seeks to rephrase the problem of generating a new image of “dog” into the problem of generating a random vector in the N dimensional vector space that follows the “dog probability distribution”
Deep Convolutional Generative Adversarial Network (DCGAN)
Code for DCGAN Implementation on MNIST
A DCGAN focuses on deep convolutional networks in places of fully-connected networks but conceptually work the same as GANs.
The general architecture of a DCGAN looks like this:  </br> These convolutional nets find areas of correlation within images and looks for spatial correlations, enabling it to be more fitting for image/video data. In addition, DCGANs also experience higher stability during training than GANs, giving you possibly an easier time at building a GAN.
</br> These convolutional nets find areas of correlation within images and looks for spatial correlations, enabling it to be more fitting for image/video data. In addition, DCGANs also experience higher stability during training than GANs, giving you possibly an easier time at building a GAN.
I built a DCGAN for the first time as an interest project and met with some challenges during training. While google serves as a wonderful resource for helping you solve problems associated to GANs, I wasn’t able to find a comprehensive compilation of the respective solutions for some problems in building a GAN.Thus, this is my attempt at illustrating my entire journey & perhaps how I’ve overcame my obstacles might help you too!
P.S If you’re building a GAN and utilizing it on a more complex dataset, I would recommend trying it out on a simple MNIST dataset first before proceeding. This way, you’ll know that your model works brilliantly.
Main Issues
The main issues I faced after building the model infrastructure was that:
- I noticed that my discriminator loss converges rapidly to zero thus preventing the generator from learning
- Adversarial loss decreases to 0 almost immediately after initiation all possibly attributed to the instability of building a GAN/DCGAN.
 Fig 1. Epoch v Loss
Fig 1. Epoch v Loss
Solutions
What I tried and what worked:
1. Try implementing weight initialization
2. Addition of noise to both input and fake images
3. When training either discriminator/generator, hold the generator/discriminator values constant
- Helped not to pre-train the discriminator
- Changed convolutional filter size to 3x3, was previously 5x5 (I’ve seen most places put this at 4)
- Reduced depths of conv layers to a consistent value of 128 for the discriminator improved the model
- added and lowered dropout values (should be ideally kept around 0.3-0.6)
In particular, 1, 2 and 3 are really popular solutions cited in most places.
Generally, GANs are highly unstable and require proper design to prevent either sides of the GAN to overpower each other. When this happens, the discriminator might return values close 0 or 1 causing the generator to struggle to read the gradient. Hence, altering the respective learning rates could help in training.
My model seemed to work fine after I adjusted the different points above. However, there are also additional things you could try that might help if you’e still having some issues.
What you could additionally try:
- Flipping the labels!
- Don’t stop training early, unless discriminator loss approaches 0 fairly quickly
- I’ve learnt that GANs take an excruciatingly long time to train and too stopping the training early might be disadvantageous
Results
Final architecture that worked for 28x28 images, following this paper:
** differently sized images may require different parameter changes
Loss values were also consistently low: 
The generated image obtained at epoch 0 was incredibly different from the generated image obtained at epoch 4000:


However, the image resolution/the generation of images could still be vastly improved. The numbers are discernible but still blurry and could be more concise. Any tips and comments are welcomed and do reach out, perhaps even running the model for more epochs might make the images better. (People have noted that their implementations have often needed to run for more epochs than predicted.)
Conclusions
Summary of architectural guidelines for stable Deep Convolutional GANs:
• Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
• Use batchnorm in both the generator and the discriminator.
• Remove fully connected hidden layers for deeper architectures.
• Use ReLU activation in generator for all layers except for the output, which uses Tanh.
• Use LeakyReLU activation in the discriminator for all layers.
The original paper also gives a really good explanation as to how they attained the respective guidelines, it serves as a very interesting read and I would definitely recommend!
I am, of course, really oversimplifying what GANs are and I do recommend reading more material to find out more!
An overview paper
GANs for the non-technical
Fantastic GANs and where to find them
Keeping up with GANs